
티스토리 뷰
독립적인 실행
자바의 대표적인 특징 중 하나는 독립적인 실행이 가능하다는 것이다
자바 같은 경우 다른 일반적인 프로그램과 다르게 OS와 Program 사이에서 JVM(Java Virtual Machine)이 실행된다
이는 물리적 머신을 소프트웨어로 구현하여 Java 프로그램을 실행할 수 있게 해주는 추상 컴퓨팅 시스템이다

이로써 어떠한 프로그램을 만든다고 하더라도 JVM을 통해 각기 다른 운영체제에서 똑같이 구동을 할 수 있다
(하지만 만병통치약이 없듯이 JVM 또한 결국 OS 위에서 실행되기 때문에 플랫폼에 따라 호환되는 JVM을 실행시켜주어야 한다)
Byte Code
사용자가 작성한 자바 코드가 JVM으로 가기 전에 한가지 작업이 필요한데
우리가 이해할 수 있는 "자바언어"를 작성하였듯이 Java Compiler가 JVM이 이해할 수 있는 "Byte Code"로 이를 변환해주어야 한다

하지만 이렇게 컴파일 된 Byte Code도 기계어는 아니기 때문에 OS에서 바로 실행은 되지 않는다
이제 이 Byte Code로 JVM이 어떻게 구동되는지 구조와 원리를 살펴보자
Class Loader
자바는 동적로드, 즉 Compile 타임이 아니라 Run 타임에 클래스를 처음으로 참조할 때 해당 클래스를 로드하고 링크하는 특징이 있다
이 동적 로드를 담당하는 부분이 JVM의 Class Loader이다
(좀 더 간단하게 풀어보자면 Class Loader는 Byte Code를 읽어 들여 class 객체를 생성하고 JVM의 메모리 영역인 Runtime Data Area로 이동시킨다)
Class Loader 특징은 보통 5가지로 나뉜다
계층구조
1. Bootstrap Class Loader
JVM을 기동할 때 생성되며, Object 클래스들을 비롯하여 Java API들을 로드한다
다른 Class Loader와 달리 Java가 아니라 네이티브 코드로 구현되어 있고 로더 중 우선순위가 가장 높다
(rt.jar 이외의 클래스)
2. Extension Class Loader
기본 Java API를 제외한 확장 클래스들을 로드한다
다양한 확장 기능 등을 여기서 로드하게 된다
(ext 폴더(jre / lib)에 있는 클래스를 로드)
3. System Class Loader
Bootstrap과 Extension Class Loader가 JVM 자체의 구성요소들을 로드한다면
System Class Loader는 Application Class들을 로드한다
또한 사용자가 지정한 $CLASSPATH 내의 클래스들을 로드한다
(환경변수 등을 로드)
4. User-Defined Class Loader
애플리케이션 사용자가 직접 코드상에서 생성하여 사용하는 Class Loader이다

여기서 WAS(Web Application Server)와 같은 프레임워크는 앱 애플리케이션과 엔터프라이즈 애플리케이션이
서로 독립적으로 동작하게 하기 위해 User-Defined Class Loader를 사용한다
즉 Class Loaderd의 위임 모델을 통해 애플리케이션의 독립성을 보장하는 것이다
이와 같은 구조는 WAS 벤더마다 다른 형태의 계층 구조를 사용하고 있다고 한다
위임모델
Class Loader가 아직 로드되지 않은 클래스를 찾으면 아래와 같은 과정을 거쳐 클래스를 로드하고 링크하고 초기화한다
1. Loading
클래스를 파일에서 가져와서 JVM의 메모리에 로드한다
2. Verifying
Byte Code 검증 기는 생성된 바이트 코드가 올바른지 여부를 검증한다, 검증이 실패하면 검증 오류가 발생한다
3. Preparing
클래스가 필요로 하는 메모리를 할당하고 클래스에서 정의된 필드, 메서드, 인터페이스들을 나타내는 데이터 구조를 준비한다
4. Resolving
클래스의 상수 pool 내 모든 심볼릭 레퍼런스를 디렉트 레퍼런스로 변경한다
(*심볼릭 레퍼런스 : 기본 자료형(primitive data type)을 제외한 모든 타입(클래스와 인터페이스)을
명시적인 메모리 주소 기반의 레퍼런스가 아니라 심볼릭 레퍼런스를 통해 참조한다)
5. Initializing
클래스 변수들을 적절한 값으로 초기화한다 즉 statitc initializer들을 수행하고 static 필드들을 설정된 값으로 초기화한다

가시성
하위 Class Loader는 상위 Class Loader의 클래스를 찾을 수 있지만 상위는 하위를 찾을 수 없다
언로드 불가
Class Loader는 클래스를 로드할 수는 있지만 Unload 할 수는 없다
언로드 대신 현재 Class Loader를 삭제하고 아예 새로운 Class Loader를 생성하는 방법을 사용할 수 있다
Runtime Data Areas
런 타임 영역은 5가지로 나뉘는데 Method Area / Heap Area / JVM Stack / PC Registers / Native Method Stack으로 나뉜다
이 중에 Method Area / Heap Area는 모든 스레드가 공유하며 나머지 영역들은 스레드마다 각각 생성된다
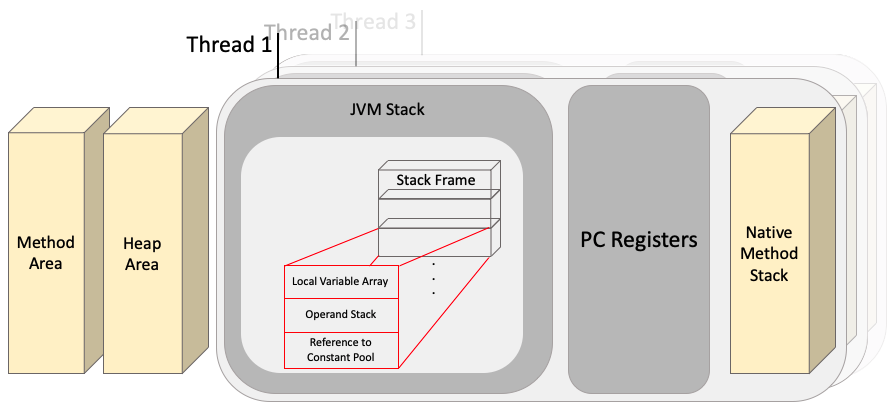
1. Method Area (메서드 영역)
Class Loader가 클래스 파일을 읽어오면 클래스 정보를 파싱 해서
정적 변수를 포함한 모든 클래스 수준의 데이터가 저장되는 곳이다
2. Heap Area (힙 영역)
프로그램을 실행하면서 생성 한 모든 객체와 해당 인스턴스 변수 그리고 배열이 저장되는 곳이다
3. PC Registers
각 스레드는 메서드를 실행하고 있고, PC는 그 메서드 안에서 몇 번째 줄을 실행해야 하는지 나타내는 역할을 한다
즉 현재 수행 중인 JVM 명령 주소를 저장하는 공간이다
4. JVM Stack
각 스레드마다 하나씩 존재하며 스레드가 시작될 때 생성된다
모든 메서드 호출에 대한 하나의 항목이 Stack Frame(스택 프레임)이라고 하는 스택 메모리에 만들어지게 되고
모든 로컬 변수가 스택 메모리에 생성된다, 스택 영역은 공유 리소스가 아니기 때문에 스레드 안전 영역이다
" { " 와 같이 여는 중괄호를 만날 때마다 스택 프레임이 하나씩 생기고 " } " 닫는 중괄호를 만나게 되면 스택 프레임이 사라지게 된다
이는 메서드뿐만 아니라 if문 , 반복문 등도 모두 스택 프레임이 생기게 된다
외부 스택 프레임에서는 내부 스택 프레임의 변수에 접근하는 것이 불가능하다 하지만 반대는 가능하다 쉽게 생각하면 메서드 안에
for문 스택 프레임을 만든 경우 for문에서는 자신을 호출한 메서드의 변수는 사용 가능하나 메서드에서는 for문에서 선언한 변수를 사용할 수 없다
메서드를 호출하는 것은 별개의 스택 프레임이기 때문에 스택 프레임을 넘어서 접근할 수 없다

스택 프레임은 다음 세 가지 하위 항목으로 나뉜다
• Local Varialbe Array (로컬 변수 배열)
로컬 변수 배열은 메서드의 지역 변수들을 갖는다 (this / int a / String c . . .)
• Operand Stack (오퍼랜드 스택)
오퍼랜드 스택은 메서드 내 계산을 위한 작업 공간이다
• Reference to Constant Pool
각 클래스와 인터페이스의 상수뿐만 아니라 메서드와 필드에 대한 모든 레퍼런스까지 감고 있는 테이블이다
즉 어떤 메서드나 필드를 참조할 때 JVM은 런타임 상수 풀을 통해 해당 메서드나 필드의 실제 메모리상 주소를 찾아서 참조한다
5. Native Method Stack
Native Method는 Java Byte Code가 아닌 다른 언어로 작성된 실제 실행할 수 있는 기계어를 실행할 때 사용한다
Execution Engine (실행 엔진)
인간이 이해할 수 있는 언어 Java는 Javac(Java Compiler)를 통해 JVM이 이해할 수 있는 Byte Code로 변환되었다
마지막으로는 이 Byte Code를 기계가 이해할 수 있는 언어로 변환하여 한 줄 한줄 실행되게 되는데 이를 수행하는 것이 실행 엔진이다

1. Interpreter
Byte Code를 기계가 이해할 수 있도록 한줄 한줄 컴파일하여 Narive Code로 변환하여 실행한다
이때 중복되는 Byte Code들에 대해서도 매번 컴파일을 하게 되면 매우 비효율적이며 Running Time도 길어지게 된다
이러한 중복되는 Byte Code에 대해서는 JIT Compiler를 사용한다
2. JIT(Just In Time) Compiler 또는 Dynamic translation 동적 번역
JIT 컴파일러의 핵심은 같은 코드를 매번 해석하지 않고 실행할 때 컴파일하면서 해당 코드를 실행한다
구조는 아래와 같다
• IR(Intermediate Representation) Code Generator
Byte Code와 Native Code의 중간 단계의 표현인 IR (Intermediate Representation) 코드를 생성한다
• Code Optimizer
IR Code Generator에서 생성된 코드를 최적화하는 작업을 한다
• Target Code Generator
Native Code를 생성한다
• Profiler
메서드가 여러 번 호출되는지의 여부를 찾는 역할을 한다
3. Garbage Collection
Java의 경우 별도로 메모리 관리를 하지 않아도 되는데, 바로 이 Garbage Collection (GC) 덕분이다
GC는 Stack에 있는 모든 변수를 스캔하면서 각각 어떤 객체를(Heap에 있는) 참조하고 있는지 찾아서 마킹을 한다
이때 마킹되지 않은 객체 즉 참조되지 않은 객체를 수집하고 제거하며 메모리를 관리한다
그 외
1. JNI (Java Native Interface)
Native Method Libraries와 상호 작용하며 실행 엔진에 필요한 Native Libraries를 제공한다
즉 JVM에 의해 실행되는 코드 중 Native Code를 호출하거나 호출될 수 있도록 만든 일종의 프레임워크이다
2. Native Method Libraries
Native Method 실행에 필요한 원시 라이브러리의 모음집이다
마지막으로 JVM의 전체 동작 구조를 정리해보면 아래와 같다



개인 학습을 위해 작성되는 글입니다.
제가 잘못 알고 있는 점에 대한 지적 / 더 나은 방향에 대한 댓글을 환영합니다.
참조 링크:
https://postitforhooney.tistory.com/entry/JavaJVM-JVM-%EC%9D%B4%ED%95%B4%EB%A5%BC-%ED%86%B5%ED%95%9C-Java-%EC%9E%91%EB%8F%99%EC%9B%90%EB%A6%AC-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
https://d2.naver.com/helloworld/1230
https://swk3169.tistory.com/181
https://steady-snail.tistory.com/67
https://inspirit941.tistory.com/296
https://www.youtube.com/watch?v=AWXPnMDZ9I0&t=339s
https://www.youtube.com/watch?v=UzaGOXKVhwU
https://ko.wikipedia.org/wiki/JIT_%EC%BB%B4%ED%8C%8C%EC%9D%BC
https://medium.com/@ahn428/java-jit-%EC%BB%B4%ED%8C%8C%EC%9D%BC%EB%9F%AC-c7d068e29f45
https://www.youtube.com/watch?v=vZRmCbl871I
참조 서적:
스프링 입문을 위한 자바 객체지향의 원리와 이해 - 김종민 저
'Java' 카테고리의 다른 글
| [JAVA] DTO와 VO의 차이 (1) | 2021.10.01 |
|---|---|
| [JAVA] JAR 와 WAR (0) | 2021.08.23 |
| [JAVA] OOP(Object-Oriented Programming) 객체지향프로그래밍 (2) (0) | 2021.08.05 |
| [JAVA] OOP(Object-Oriented Programming) 객체지향프로그래밍 (1) (0) | 2021.08.05 |
- Total
- Today
- Yesterday
- DTO와 VO의 차이
- @ResponseStatus
- ExceptionHandlerExceptionResolver
- DefaultHandlerExceptionResolver
- Spring API Error
- 캐시
- 맨코
- 제이쿼리 위치탐색선택자
- 제이쿼리 인접 관계 선택자
- application/x-www-form-urlencoded
- 제이쿼리 탐색선택자
- 세션
- 제이쿼리 직접 선택자
- Spring TypeConverter
- OOP
- jQuery 직접 선택자
- http
- spring
- Cache
- Spring MVC
- Session
- Spring Container
- 제이쿼리 기본 선택자
- 제이쿼리란
- maenco
- cookie
- ResponseStatusExeceptionResolver
- 쿠키
- @ExceptionHandlere
- uri
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |